- Published on
Introduction to Gaussian Process Regression
- Authors

- Name
- Jan Hardtke
Gaussian processes are a robust and flexible method in machine learning, capable of leveraging prior information to make predictions. Their primary use is in regression, where they model data by fitting. However, their utility goes beyond regression, extending to tasks like classification and clustering. When faced with training data, countless functions can potentially describe it. Gaussian processes tackle this challenge by assigning a likelihood to each function, with the average of this distribution serving as the most plausible representation of the data. Moreover, their probabilistic framework naturally incorporates prediction uncertainty, providing insights into the confidence of the results.
Introductory concepts
Gaussian processes are built upon the mathematical framework of the multivariate Gaussian distribution, which extends the familiar Gaussian (or normal) distribution to multiple random variables that are jointly normally distributed. This distribution is characterized by two key components: a mean vector, , and a covariance matrix, , which describes the relationships between pairs of variables. Before diving into these concepts, we will first cover some fundamental terms from probability theory to ensure we have a shared understanding.
Generally, a multivariate Gaussian distribution is expressed as:
where is a vector of random variables.
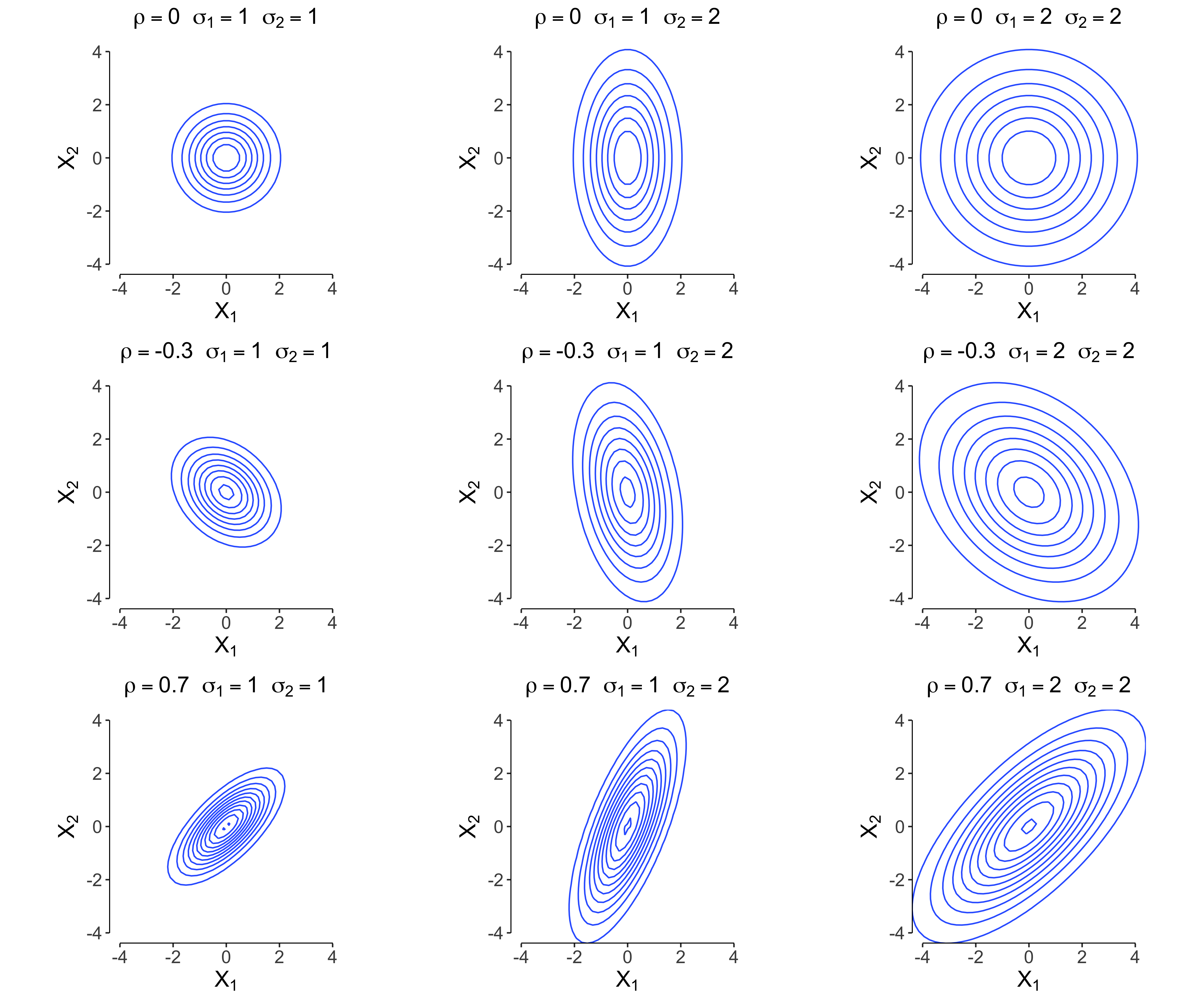
The covariance matrix determines the shape of the distribution and, in the 2D case, can be represented as:
Contour plots of the multivariate Gaussian distribution illustrate how affects the spread and orientation of the distribution. An example of such plots for different covariance matrices is shown in the figure below, demonstrating how the covariance influences the relationships between variables.
Conditioning
Suppose a joint dristribution of two vectors of gaussian random variables and
The covariance matrices, such as , are themselves matrices, ensuring that the final covariance matrix has a size of . We can derive the conditional multivariate distributions using the following expressions:
or
Marginalization
Another important concept is marginalization. Marginalization over a random variable in a joint distribution involves summing (or integrating) over all possible values of the other variable in the conditional distribution.
For example, given two vectors of Gaussian random variables:
and their joint distribution , we can marginalize over as follows:
We can observe the differences between conditioning and marginalization in the figure below.
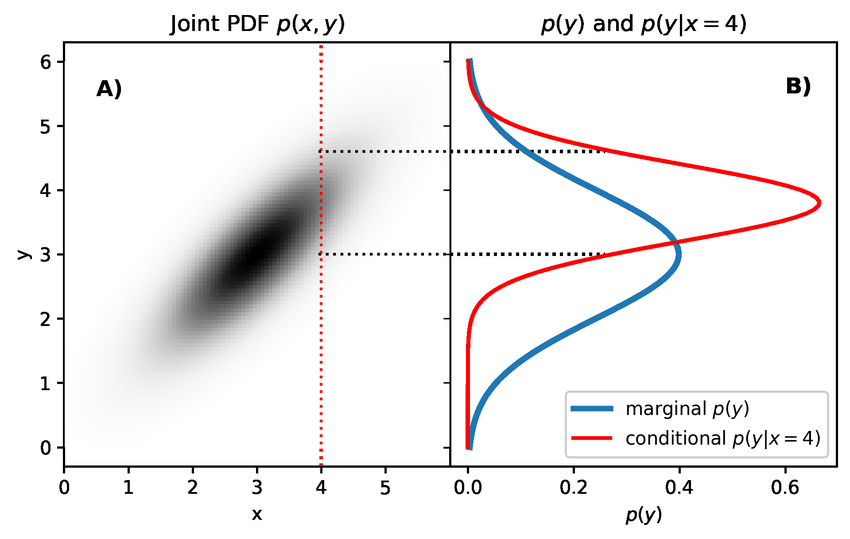
As shown, conditioning involves slicing through the distribution at a specific value, resulting in a distribution with one less dimension. In this case, it becomes a 1D distribution, which is a simple normal distribution. Marginalization on the other hand acts like projecting the whole 2D distribution into one dimension, in this case .
Gaussian processes
Now that we have covered the basic concepts, we can discuss how to use them to formulate the ideas behind Gaussian processes and Gaussian process regression. The basic idea is as follows: given a set of sample positions of a function , we aim to determine , where is the i-th entry of a random vector . This vector follows a multivariate normal distribution, meaning:
For simplicity, we often assume . However, calculating involves another mathematical concept called a kernel function.
The kernel function , defined as , is a measure of similarity between its inputs. A high output value for indicates high similarity between inputs, and vice versa.
In our case, the kernel function is used to compute the covariance matrix of the multivariate normal distribution. To calculate each entry of , we assume:
meaning that the covariance between two function values and is high when their corresponding inputs and are close together.
Common Kernel Functions
Below are some commonly used kernel functions in the context of Gaussian processes, some of them take hyperparameters like or :
- RBF Kernel:
- Periodic Kernel:
- Linear Kernel:
Different values for hyperparameters make the similarity measure of the kernels more or less strict, leading to sharper or smoother functions in the process.
Now that we have a method to compute the covariance matrix , we can sample a random function by drawing a sample from the multivariate normal distribution . Each entry in the sampled vector corresponds to the value of at , meaning
Gaussian Processes for Regression
We have now covered the fundamentals of Gaussian processes. Next, we will extend our understanding to explore how Gaussian processes can be applied to solve regression tasks.
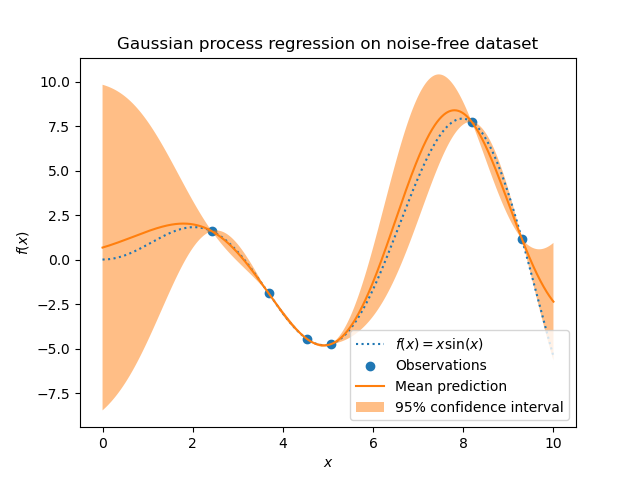
Before diving into the technical details, our objective is clear: to model a distribution of functions that pass through our training points (as shown in the image above) and are therefore able to explain the distribution of our data.
Now, let represent our test points and our training points. We aim to model the posterior distribution , which answers the question:
"What possible values for are there, given the training points in ?"
This is where conditioning comes into play. Computing the distribution provides us with functions that pass precisely through the points in . Conceptually, we can think of this as slicing through a -dimensional normal distribution, fixing the values at locations as constants. This results in a -dimensional normal distribution.
As we know it is easy to calculate distribution for with
From our prerequisites, we know that can be calculated as:
This is the final distribution from which we can sample. It provides functions that pass through all points in and whose behavior for is modeled by (see image above). The figure also illustrates the 95% confidence interval () and the mean function. In practice, the mean function is often the most useful for regression or prediction tasks, as it provides the expected value of the output based on the given data. Getting the mean function as well as the confidence interval is really easy once we obtained the and for . We can just query them at the i-th point and get the respective and . This wil result in
where the second equality stems from the fact that we assume and . For the standart deviation we get
Doing this for every point will result in the same figure we saw above.
So in summary, gaussian processes are a flexible framework for regression, where functions are modeled as samples from a multivariate normal distribution. A kernel function is used to compute the covariance matrix , which encodes the similarity between inputs. The posterior distribution then allows us to generate functions that pass through the training points while predicting the behavior for test points . In the end, we use the mean function provided by this posterior because it represents the most likely prediction for the underlying function.